Fossil Concepts
1.0 Introduction
Fossil is a software configuration management system. Fossil is software that is designed to control and track the development of a software project and to record the history of the project. There are many such systems in use today. Fossil strives to distinguish itself from the others by being extremely simple to setup and operate.
This document is intended as a quick introduction to the concepts behind Fossil.
See also:
2.0 Composition Of A Project
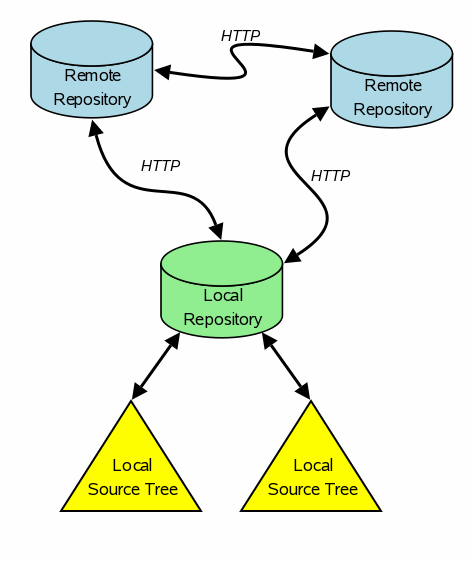
A software project normally consists of a "source tree". A source tree is a hierarchy of files that are used to generate the end product. The source tree changes over time as the software grows and expands and as features are added and bugs are fixed. A snapshot of the source tree at any point in time is called a "version" or "revision" or a "baseline" of the product. In Fossil, we use the name "check-in".
A "repository" is a database that contains copies of all historical check-ins for a project. Check-ins are normally stored in the repository in a highly space-efficient compressed format (delta encoding). But that is an implementation detail that you the user need not worry over. Think of the repository as a safe place where all your old check-ins are securely stored away and available for retrieval whenever you need them.
A repository in Fossil is a single file on your disk. This file might be rather large (dozens or hundreds of megabytes for a large or long running project) but it is nevertheless just a file. You can move it around, rename it, write it out to a memory stick, or do anything else you normally do with files.
Each source tree that is controlled by Fossil is associated with a single repository on the local disk drive. You can tie two or more source trees to a single repository if you want (though one tree per repository is the most common configuration.) So a single repository can be associated with many source trees, but each source tree is associated with only one repository.
Fossil source trees may not overlap. A Fossil source tree is identified by a file named "_FOSSIL_" (or ".fslckout", but this article will always use the name "_FOSSIL_") in the root directory of the source tree. Every file that is a sibling of _FOSSIL_ and every file in every subfolder is considered potentially a part of the source tree. The _FOSSIL_ file contains (among other things) the pathname of the repository with which the source tree is associated. On the other hand, the repository has no record of its source trees. So you are free to delete a source tree or move it around without consequence. But if you move or rename or delete a repository, then any source trees associated with that repository will no longer be able to locate their repository and will stop working.
When multiple developers are working on the same project, each developer typically has his or her own local repository and an associated source tree in which to work. Developers share their work by "syncing" the content of their local repositories either directly or through a central server. Changes can "push" from the local repository into a remote repository. Or changes can "pull" from a remote repository into a local repository. Or one can do a "sync" which is a shortcut for doing both a push and a pull at the same time. Fossil also has the concept of "cloning". A "clone" is like a "pull", except that instead of beginning with an existing local repository, a clone begins with nothing and creates a new local repository that is a duplicate of a remote repository.
Communication between repositories is via HTTP. Remote repositories are identified by URL. You can also point a web browser at a repository and get human-readable status, history, and tracking information about the project.
2.1 Identification Of Artifacts
A particular version of a particular file is called an "artifact". Each artifact has a universally unique name which is the SHA1 hash of the content of that file expressed as 40 characters of lower-case hexadecimal. Such a hash is referred to as the Artifact Identifier or Artifact ID for the artifact. The SHA1 algorithm is created with the purpose of providing a highly forgery-resistant identifier for a file. Given any file it is simple to find the artifact ID for that file. But given a artifact ID it is computationally intractable to generate a file that will have that Artifact ID.
Artifact IDs look something like this:
6089f0b563a9db0a6d90682fe47fd7161ff867c8
59712614a1b3ccfd84078a37fa5b606e28434326
19dbf73078be9779edd6a0156195e610f81c94f9
b4104959a67175f02d6b415480be22a239f1f077
997c9d6ae03ad114b2b57f04e9eeef17dcb82788
When referring to an artifact using Fossil, you can use a unique prefix of the artifact ID that is four characters or longer. This saves a lot of typing. When displaying artifact IDs, Fossil will usually only show the first 10 digits since that is normally enough to uniquely identify a file.
Changing (or adding or removing) a single byte in a file results in a completely different artifact ID. And since the artifact ID is the name of the artifact, making any change to a file results in a new artifact. In this way, artifacts are immutable.
A repository is really just an unordered collection of artifacts. New artifacts can be added to the repository, but existing artifacts can never be removed. (Well, almost never. There is a "shunning" mechanism that allows spam or other inappropriate content to be removed if absolutely necessary, but such removal is discouraged.) Fossil is designed in such a way that it can be handed a set of artifacts in any order and it can figure out the relationship between those artifacts and reconstruct the complete development history of a software project.
2.2 Manifests
Associated with every check-in is a special file called the "manifest". The manifest is a listing of all other files in that source tree. The manifest contains the (complete) artifact ID of the file and the name of the file as it appears on disk, and thus serves as a mapping from artifact ID to disk name. The artifact ID of the manifest is the identifier for the entire check-in. When you look at a "timeline" of changes in Fossil, the ID associated with each check-in or commit is really just the artifact ID of the manifest for that check-in.
The manifest file is not normally a real file on disk. Instead, the manifest is computed in memory by Fossil whenever it needs it. However, the "fossil setting manifest on" command will cause the manifest file to be materialized to disk, if desired. Both Fossil itself, and SQLite cause the manifest file to be materialized to disk so that the makefiles for these project can read the manifest and embed version information in generated binaries.
Fossil automatically generates a manifest whenever you "commit" a new check-in. So this is not something that you, the developer, need to worry with. The format of a manifest is intentionally designed to be simple to parse, so that if you want to read and interpret a manifest, either by hand or with a script, that is easy to do. But you will probably never need to do so.
In addition to identifying all files in the check-in, a manifest also contains a check-in comment, the date and time when the check-in was established, who created the check-in, and links to other check-ins from which the current check-in is derived. There is also a couple of checksums used to verify the integrity of the check-in. And the whole manifest might be PGP clearsigned.
2.3 Key concepts
- A check-in is a set of files arranged in a hierarchy.
- A repository keeps a record of historical check-ins.
- Repositories share their changes using push, pull, sync, and clone.
- A particular version of a particular file is an artifact that is identified by an artifact ID.
- Artifacts tracked by Fossil are inherently immutable.
- Fossil automatically generates a manifest file that identifies every artifact in a check-in.
- The artifact ID of the manifest is the identifier of the check-in.
3.0 Fossil - The Program
Fossil is software. The implementation of Fossil is in the form of a single executable named "fossil" (or "fossil.exe" on Windows). To install Fossil on your system, all you have to do is obtain a copy of this one executable file (either by downloading a pre-compiled version or compiling it yourself) and then putting that file somewhere on your PATH.
Fossil is completely self-contained. It is not necessary to install any other software in order to use Fossil. You do not need CVS, gzip, diff, rsync, Python, Perl, Tcl, Java, apache, PostgreSQL, MySQL, SQLite, patch, or any similar software on your system in order to use Fossil effectively. You will want to have some kind of text editor for entering check-in comments. Fossil will use whatever text editor is identified by your VISUAL environment variable. Fossil will also use GPG to clearsign your manifests if you happen to have it installed, but Fossil will skip that step if GPG missing from your system. You can optionally set up Fossil to use external "diff" programs, though Fossil has an excellent built-in "diff" algorithm that works fine for most people. If you happen to have Tcl/Tk installed on your system, Fossil will use it to generate a graphical "diff" display when you use the --tk option to the "diff" command, but this too is entirely optional.
To uninstall Fossil, simply delete the executable.
To upgrade an older version of Fossil to a newer version, just replace the old executable with the new one. You might need to run "fossil all rebuild" to restructure your repositories after an upgrade. Running "all rebuild" never hurts, so when upgrading it is a good policy to run it even if it is not strictly necessary.
To use Fossil, simply type the name of the executable in your shell, followed by one of the various built-in commands and arguments appropriate for that command. For example:
fossil help
In the next section, when we say things like "use the help command" we mean to use the command name "help" as the first token after the name of the Fossil executable, as shown above.
4.0 Workflow
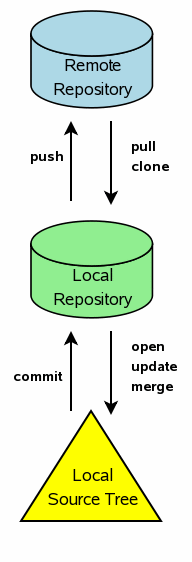
Fossil has two modes of operation: "autosync" and "manual-merge" Autosync mode is reminiscent of CVS or SVN in that it automatically keeps your changes in synchronization with your co-workers through the use of a central server. The manual-merge mode is the standard workflow for GIT or Mercurial in that your local repository develops independently of your coworkers and you share and merge your changes manually. An interesting feature of Fossil is that it supports both autosync and manual-merge work flows.
The default setting for Fossil is to be in autosync mode. You can change the autosync setting or check the current autosync setting using commands like:
fossil setting autosync on
fossil setting autosync off
fossil settings
By default, Fossil runs with autosync mode turned on. The authors finds that projects run more smoothly in autosync mode since autosync helps to prevent pointless forking and merging and helps keeps all collaborators working on exactly the same code rather than on their own personal forks of the code. In the author's view, manual-merge mode should be reserved for disconnected operation.
4.1 Autosync Workflow
- Establish a local repository using either the new command to start a new project, or the clone command to make a clone of a repository for an existing project.
-
Establish one or more source trees using the open command with the name of the repository file as its argument.
-
The open command in the previous step populates your local source tree with a copy of the latest check-in. Usually this is what you want. In the rare cases where it is not, use the update command to switch to a different check-in. Use the timeline or leaves commands to identify alternative check-ins to switch to.
-
Edit the code. Add new files to the source tree using the add command. Omit files from future check-ins using the rm command. (Even when you remove files from future check-ins, those files continue to exist in historical check-ins.) Test your changes.
-
Create a new check-in using the commit command. You will be prompted for a check-in comment and also for your GPG key if you have GPG installed. The commit copies the edits you have made in your local source tree into your local repository. After your commit completes, Fossil will automatically push your changes back to the server you cloned from or whatever server you most recently synced with.
-
When your coworkers make their own changes, you can merge those changes into your local local source tree using the update command. In autosync mode, update will first go back to the server you cloned from or with which you most recently synced, and pull down all recent changes into your local repository. Then it will merge recent changes into your local source tree. If you do an update and find that it messes something up in your source tree (perhaps a co-worker checked in incompatible changes) you can use the undo command to back out the changes.
-
Repeat all of the above until you have generated great software.
4.2 Manual-Merge Workflow
When autosync is disabled, the commit command is decoupled from push and the update command is decoupled from pull. That means you have to do a few extra steps in order to accomplish the push and pull tasks manually.
- Establish a local repository using either the new command to start a new project, or the clone command to make a clone of a repository for an existing project. The default setting for a new repository is with autosync on, so you will need to turn it off using the setting autosync off command with a -R option to specify the repository.
-
Establish one or more source trees by changing your working directory to where you want the root of the source tree to be, then issuing the open command with the name of the repository file as its argument.
-
The open command in the previous step populates your local source tree with a copy of the latest check-in. Usually this is what you want. In the rare cases where it is not, use the update command to switch to a different check-in. Use the timeline or leaves commands to identify alternative check-ins to switch to.
-
Edit the code. Add new files to the source tree using the add command. Omit files from future check-ins using the rm command. (Even when you remove files from future check-ins, those files continue to exist in historical check-ins.) Test your changes.
-
Create a new check-in using the commit command. You will be prompted for a check-in comment and also for your GPG key if you have GPG installed. The commit copies the edits you have made in your local source tree into your local repository.
-
Use the push command to push your changes out to a server where your co-workers can access them.
-
When co-workers make their own changes, use the pull command to pull those changes into your local repository. Note that pull does not move the changes into your local source tree, only into your local repository.
-
Once changes are in your local repository, use the update command to merge them to your local source tree. If you merge in some changes and find that the changes do not work out or are not to your liking, you can back out the changes using the undo command.
-
If two or more people ran "commit" against the same check-in, this will result in a fork which you may want to resolve by running merge followed by another commit.
-
Repeat all of the above until you have generated great software.
5.0 Setting Up A Fossil Server
With other configuration management software, setting up a server is a lot of work and normally takes time, patience, and a lot of system knowledge. Fossil is designed to avoid this frustration. Setting up a server with Fossil is ridiculously easy. You have four options:
Stand-alone server. Simply run the fossil server or fossil ui command from the command-line.
CGI. Install a 2-line CGI script on a CGI-enabled web-server like Apache.
SCGI. Start an SCGI server using the fossil server --scgi command for handling SCGI requests from web-servers like Nginx.
Inetd or Stunnel. Configure programs like inetd, xinetd, or stunnel to hand off HTTP requests directly to the fossil http command.
See the How To Configure A Fossil Server document for details.
6.0 Review Of Key Concepts
- The fossil program is a self-contained stand-alone executable. Just put it somewhere on your PATH to install it.
- Use the clone or new commands to create a new repository.
- Use the open command to create a new source tree.
- Use the add and rm or delete commands to add and remove files from the local source tree.
- Use the commit command to create a new check-in.
- Use the update command to merge in changes from others.
- The push and pull commands can be used to share changes manually, but these things happen automatically in the default autosync mode.